
{kind=link}
In un evento per giornalisti e analisti a Los Angeles, in California, AMD ha rivelato maggiori dettagli sui processori mobili Ryzen AI 300 annunciati al Computex e sulla tecnologia che contengono.
annuncio
I dati principali delle due nuove CPU, Ryzen AI 9 HX 370 e Ryzen AI 9 365, sono già noti dal Computex, ma ora sono stati integrati con maggiori dettagli.
Al Techday, AMD ha anche mostrato alcuni laptop Copilot+ di Acer, Asus, HP e MSI con processori Ryzen AI 300 già annunciati al Computex. In diverse applicazioni demo, soprattutto i moduli AI – che ora sono finalmente visibili come NPU con vista di caricamento nel task manager – hanno mostrato cosa possono fare. Oltre agli strumenti AI dei produttori di notebook come StoryCube di Asus, Live Art di Acer, LMStudio di MSI e AI Companion di HP, erano in mostra anche il generatore di immagini Stable Diffusion XL Turbo e il booster AI Detailretter di Topaz Labs e dello sviluppatore Gigapixel 7. Dettagli affascinanti: Dei portatili gaming con dGPU, nessuno aveva la tecnologia Radeon Mobile.
Zen 5: Combo Base
AMD ha effettivamente sviluppato due diversi core Zen nella generazione precedente (Zen 4 + Zen 4c), che, a differenza dei core di prestazioni ed efficienza di Intel, hanno lo stesso set di istruzioni e possono quindi essere controllati in modo uniforme.
Inizialmente sono stati utilizzati nei processori server Epyc 9704 (“Bergamo”) e sono notevolmente più compatti degli originali – da qui i nomi “compatti” e “classici”. Tecnicamente i nuclei combinati sono ottimizzati per un diverso intervallo operativo sulla curva di tensione e frequenza, la cui interazione porta anche all’efficienza. Poiché la tensione operativa è il quadrato della perdita di potenza, si può sempre presumere che una tensione inferiore si traduca in un maggiore risparmio energetico rispetto a una perdita di prestazioni, il che significa che i circuiti funzionano in modo più efficiente. Se non hai più bisogno di ottimizzare per le frequenze più alte, puoi risparmiare altrove così i nuclei compatti occupano molto meno spazio rispetto alle versioni classiche.
La sezione è ora disponibile anche per gli utenti finali del Ryzen 8000G, ad esempio dell’8500G, dove i processori Zen 4c in Turbo gestiscono solo 3,7 GHz invece di 5 e sono quindi circa un quarto più lenti. Il suo chip monolitico combina due core classici con velocità di clock più elevate e quattro core compatti per una migliore reattività.
AMD combina i core Zen 5 nel Ryzen AI 300 in modo simile: quattro core Zen 5 spessi, insieme a otto set di core integrati, garantiscono le prestazioni di calcolo richieste. Tuttavia, solo il Ryzen AI 9 HX 370 di fascia alta ha dodici core completi; Il Ryzen AI 9 365 (senza l’aggiunta del modello HX di fascia alta) dovrebbe gestire una configurazione 2+8. Tuttavia, AMD non ha menzionato le velocità di clock per i core integrati nelle CPU della serie 300, che hanno una potenza di 28 W come standard. e può essere configurato tra 15 e 54 Watt.
I miglioramenti alla microarchitettura dello Zen 5 si applicano in gran parte ad entrambe le versioni base – con l’eccezione dell’AVX512, mostrata sotto.
AMD ha significativamente ridisegnato il front-end così come i moduli di esecuzione e la connettività della cache. Invece di un dispositivo, due decoder indipendenti ora elaborano quattro istruzioni in parallelo, ciascuno con la propria piccola cache contenente 6.000 istruzioni già decodificate. La cache dati L1 cresce del 50% arrivando a 48 KB (12x) senza peggiorare la latenza. Anche il percorso dei dati dalla cache L1 all’unità vettoriale è stato raddoppiato: la cache delle istruzioni L1 ora ha due porte di lettura a 32 bit e la cache dei dati L1 è connessa a 64 bit e può eseguire quattro operazioni di lettura e due operazioni di scrittura. Tutto questo viene fatto, come nel caso dei registri multipli in virgola mobile, in modo da poter sfruttare adeguatamente i moduli AVX512 a piena velocità. Come sempre, anche le previsioni sui salti verranno migliorate e le finestre non ordinate verranno ampliate. Ciò significa che è possibile elaborare e mantenere più istruzioni in parallelo.


AMD ha apportato una serie di nuove modifiche alla microarchitettura Zen 5. Ad esempio, sul front-end viene utilizzata una doppia pipeline di fetch/decode.
(Immagine: AMD)
Maggiori dettagli saranno disponibili nel prossimo numero di c’t.
AVX512 a pieno rendimento – in teoria
Come per lo Zen 4, è nuovamente presente anche l’estensione del set di istruzioni AVX512. A differenza dello Zen 4, il core Zen 5 può teoricamente eseguire l’AVX512 in un passaggio invece che in due, fornendo il doppio della potenza di calcolo per clock. Tuttavia, AMD ha mantenuto anche la possibilità di elaborare le istruzioni globali in due blocchi da 256 bit uno dopo l’altro per risparmiare spazio ed energia, come faceva Zen 4.
E questo è esattamente ciò che viene utilizzato con entrambi i chip Ryzen AI 300, come ha confermato il “Padrino di Ryzen”, lo sviluppatore capo di AMD Ryzen Mike Clark, in una serie di discussioni quando gli è stato chiesto da c’t. Eravamo interessati a come AMD avrebbe gestito la divisione tra core classici e core embedded quando fossero arrivate le istruzioni giuste: dopo tutto, i quattro core Zen 5 spessi avrebbero avuto le stesse prestazioni AVX512 delle otto versioni embedded, anche alla stessa velocità di clock.
Ma a quanto pare, questo non è stato un problema per il Ryzen AI 300, perché i core classici del Ryzen AI 300 funzionano con l’opzione di risparmio energetico per elaborare le operazioni AVX512 in due passaggi consecutivi. AMD non ha voluto rivelare se i core classici utilizzano una maschera di esposizione fisica diversa o se l’opzione AVX512 full-speed viene attivata solo tramite BIOS o tramite un fusibile bruciato. Tuttavia, tra le righe sono trapelate informazioni secondo cui i quattro core di grandi dimensioni possono accedere a una sezione da 16 MB della cache L3 da 24 MB, che lascerà solo 8 MB per gli otto core combinati.
Inoltre non hanno voluto rivelare nulla di specifico riguardo al risparmio di spazio dei core Zen 5 integrati.
Tuttavia, per le CPU desktop Ryzen 9000 dovrebbe essere utilizzata la veloce opzione AVX512, come ha sottolineato il presidente di AMD Lisa Su nel suo discorso al Computex.
RDNA 3.5: ottimizzato per laptop
Secondo AMD, AMD ha adattato la grafica integrata del Ryzen AI 300 per l’utilizzo nel segmento dei laptop sensibili al consumo energetico sulla base dell’esperienza acquisita dalla licenza concessa a Samsung.
Tre delle modifiche più importanti sono la moltiplicazione del campionamento del tessuto, il conteggio dei numeri interi e il confronto della produttività. Inoltre, il sottosistema di memoria viene migliorato, tra l’altro, riducendo gli accessi attraverso un migliore caching.
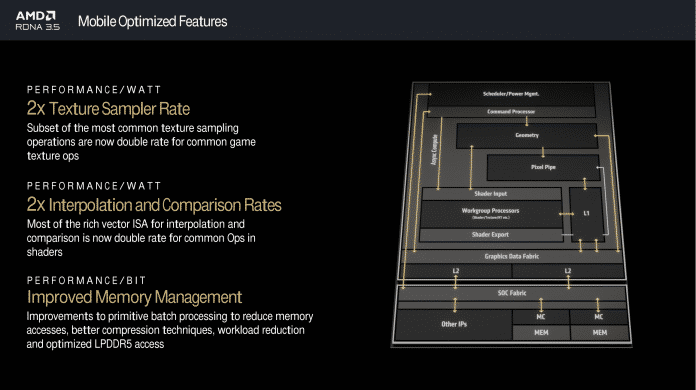
La grafica integrata è stata rifattorizzata per aumentare l’efficienza energetica, dandole così il proprio nome di architettura: RDNA 3.5. Il throughput di campionamento delle texture, numeri interi e confronto è stato raddoppiato e l’accesso alla memoria è stato migliorato.
(Immagine: AMD)
I campionatori di texture sono percorsi dati efficienti verso i moduli shader, che possono essere utilizzati anche per eseguire altri calcoli, ad esempio per effetti grafici di ray tracing, che oscurano parti dei moduli texture di AMD. Quindi questi possono funzionare in modo sincrono. La moltiplicazione di numeri interi e il confronto del throughput in unità vettoriali lasciano principalmente più tempo a disposizione per altre operazioni di calcolo, poiché le funzioni accelerate vengono spesso utilizzate per attività preparatorie: Nvidia ha apportato una modifica simile nella serie GeForce RTX 2000 “Turing” l’ha implementata.
Con un consumo energetico di 15 W, il Ryzen AI 9 HX 370 dovrebbe raggiungere prestazioni superiori di circa un terzo nel benchmark 3DMark Time Spy per DirectX 12 con 2.462 punti rispetto al Ryzen 7 8840U configurato in modo simile.
XDNA2: modulo AI ritrovato
Come il suo predecessore, il nuovo modulo AI proviene dalla divisione FPGA acquisita da AMD Xilinx, più precisamente dalla linea di prodotti Versal. AMD ha aumentato le sue prestazioni rispetto al Ryzen 8040 di circa tre volte e ora raggiunge un throughput teorico di 50 trilioni di operazioni al secondo (50 TOPS) con precisione numerica e solo leggermente inferiore quando si utilizza il nuovo formato a blocchi FP16 supportato. Con questo, AMD vuole gestire l’inferenza sui moduli XDNA per i modelli AI che hanno già una risoluzione FP16 al doppio della velocità e quasi con la stessa precisione. Ciò dovrebbe essere possibile utilizzando un esponente comune per i blocchi decimali con approssimativamente la stessa precisione nei modelli AI senza quantizzazione aggiuntiva e complessa. Vogliono fornire uno strumento di traduzione nel Blocco FP16.
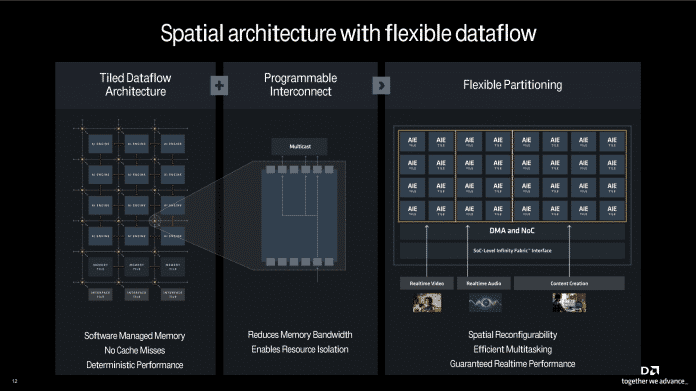
Il modulo AI XDNA2 si basa sui processori di flusso di dati Versal 2 della divisione Xilinx di AMD. Può essere partizionato per applicazioni AI e le parti inutilizzate vanno in sospensione.
(Immagine: AMD)
Il modulo XDNA2 contiene otto gruppi di quattro moduli di esecuzione che possono essere personalizzati individualmente per le applicazioni AI. Per molte applicazioni IA, come la traduzione simultanea di amplificatori o filtri video, è sufficiente che vengano eseguite in tempo reale e le prestazioni elevate non avvantaggiano l’utente ma costano solo più elettricità; Pertanto, il modulo XDNA2 può mappare le unità di esecuzione menzionate in gruppi di cinque e in un volume di applicazione. Se non c’è nient’altro da fare, i moduli rimanenti non utilizzati entrano in modalità di sospensione.
In combinazione con altri miglioramenti, il nuovo XDNA2 dovrebbe offrire un’efficienza energetica doppia rispetto al suo predecessore, il Ryzen 7040.
(Centro Tutela Ambientale)

“Lifelong beer expert. General travel enthusiast. Social media enthusiast. Zombie expert. Communicator.”